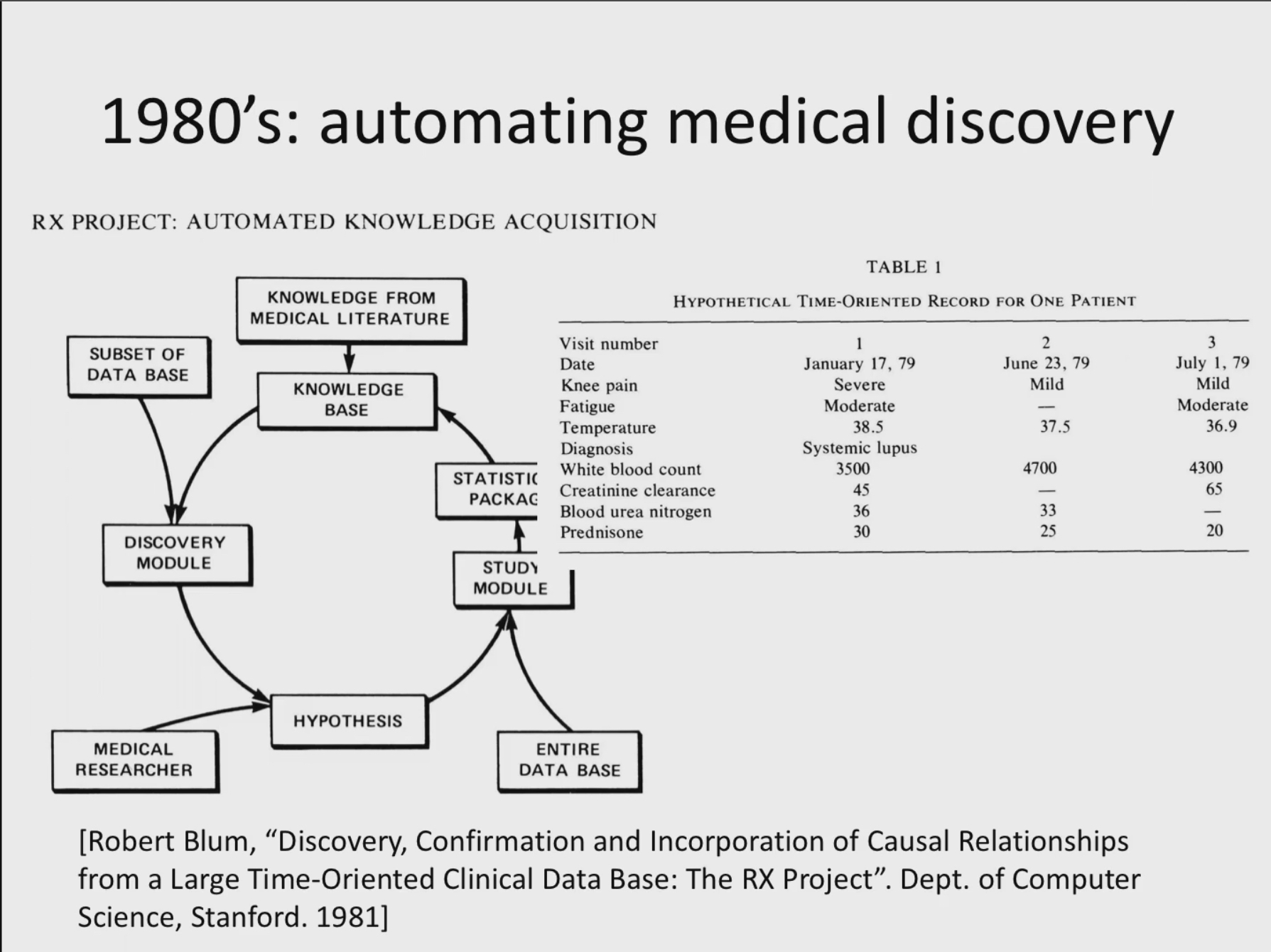
3주차 수요일 https://youtube.com/playlist?list=PLUl4u3cNGP60B0PQXVQyGNdCyCTDU1Q5j&si=iOUuKMchJz8QbFEE MIT 6.S897 Machine Learning for Healthcare, Spring 2019Instructors: David Sontag, Peter Szolovits View the complete course: https://ocw.mit.edu/6-S897S19 Introduces students to machine learning in healthcare, the...www.youtube.com 머신러닝 기술을 통해서 의료사회를 어떻게 혁신 할 수 있을까?이 분야에 관심을 갖게 된 각자의 사연들이 있는 것 같다. 암판..