25/01/13-14
벌써 랩실에 들어와 스터디를 시작한지 3주차가 되었다 !!
지난주는 강의보기 + 캐글 타이타닉⛴️문제 2.5% 안에 들기 + 3일간 특강
의 과제가 주어져서 업로드 할 수 있는 형태의 기록이 없었던 것 같아 늦어버렸다💦
2주차 랩실스터디 과제의 첫번째!
딥러닝 강의보고 스터디 후 요약(? ,,,이 아니라 더 정리 내용이 늘어나는 것 같긴 하지만)을 시작한다 ~~!
[영상]
https://youtu.be/aircAruvnKk?si=u8n_-L0-ItNT9NGy
"딥러닝"
은 컴퓨터가 사람처럼 학습하고 문제를 해결할 수 있도록 하기 위해, 뇌의 뉴런을 모방한 인공신경망을 기반으로 데이터를 분석하고 패턴을 찾아내는 기술이다.
우리는 픽셀이 다르고 밝기도 다른 3이 써져있는 그림을 봐도 우리는 모두 3이라고 인식할 수 있다
우리 눈 안의 시지각세포들이 빛 신호를 받아들이는 패턴은 서로 다른 양상을 가지는데도 불구하고 말이다.
그러나 우리의 시각피질은 이러한 차이에도 불구하고 두 개념이 같다고 가리키며, 다른 것들은 구별할 수 있다.
이러한 신비한 인간의 능력을 본떠, 다양한 차이를 극복하고 스스로 학습하며 판단할 수 있는 인공지능 기술을 소개하려고 한다.
이번 과제는 위 영상들을 보고 스터디 후 요약하기 과제였다.

위에서 잠깐 언급했 듯, '신경망'이라는 아이디어는 사람의 뇌에서 착안한 것이다.
뇌의 어떤 점을 본땄고, 뇌와 신경망이 어떤 유사점을 가지는지 알아보면 딥러닝에 대해 더 쉽게 이해할 수 있을 같다.
먼저 !! 뉴런에 대해 알아보자.
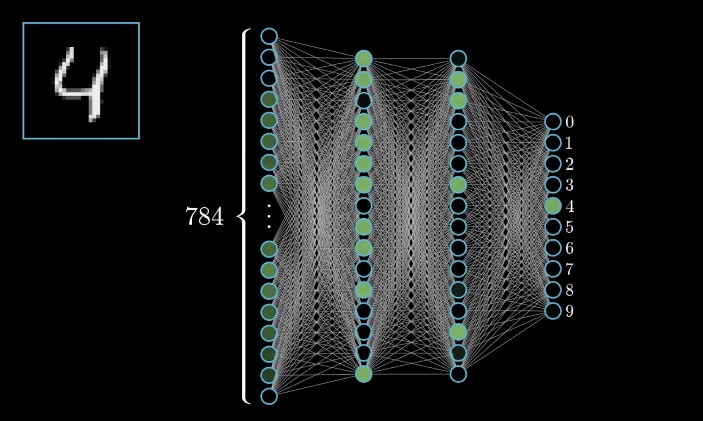
뉴런은 하나의 숫자를 담는다. (아래 사진 참고)
(뉴런이 보관한 숫자들은 입력한 이미지에 따라 결정된다. 지금 당장 이 말을 이해할 필요는 없지만, 뉴런을 이전 층의 뉴런 출력을 모두 받아서 0과 1 사이의 수를 만들어내는 함수라고 생각하는 것이 정확하긴 하다. 사실 네트워크 전체도 784개의 수를 입력받아서 10개의 수를 출력하는 함수이다. 이 복잡한 함수는 특정한 패턴을 인식하기 위해 만 3천여개의 가중치나 bias형태의 매개변수로 수 많은 벡터 행렬곱과 시그모이드 압축을 반복한다).

각 뉴런은 각 픽셀의 밝기를 나타낸다. 0.0 (검정색) ~1.0 (하얀색) 까지를 담는다.
신경망에서는 이러한 숫자들을 '입력값'이라고 부른다.
28*28 픽셀, 즉 784개의 뉴런이 신경망의 입력층을 구성하게 된다.
또한, 큰 입력값이 주어질수록 각각의 신경망이 더 큰 정도로 활성화된다.

신경망은 기본적으로 한 층에서의 활성화가 다음 층의 활성화를 유도하는 방식으로 작동한다.
정보를 처리하는 과정에서 신경망의 가장 중요한 점은, 어떻게 한 층에서의 활성화가 다른 층의 활성화를 불러일으키는지에 관한 점이다.
이러한 과정은 생물의 뉴런이 작동하는 방식과 닮아있다. 이는 몇몇의 뉴런의 활성화가 다른 뉴런의 활성화를 수반한다는 점이다.
어떻게 한 층의 활성화가 다른 층의 활성화를 불러일으키는지에 대해 ‘기계의 관점’에서 본다면 분명 수학적인 접근이 있어야 할 것이다.
잠깐 수학적인 접근을 하기 이전에 어떻게 이러한 구조가 지적으로 행동한다고 보는지 생각해봐야한다.
우리는 뭘 기대하고, 가운데 층들은 무슨 역할을 하는 것일까? 🤔💭
우리가 숫자를 인식할 때, 숫자의 각 부분들을 분리해서 인식한 후 합친다.

사진과 같이, 9의 경우 상단부분의 동그라미 모양과, 하단부분의 세로선을 분리하고 이후 합칠 수 있다.
이상적으로는 두 번째 층의 각 뉴런들이 이러한 '부분'들에 대해 대응하기를 원한다.
9라는 숫자를 동그라미와 세로 선으로 분리를 하였다 !
그러고 나니, 동그라미를 인식하는 것 또한 부가적인 질문들이 생길 수 있다.

요렇게 쪼개면 된다 !!
쪼갠 동그라미를 더 작게 쪼갠 것!

1,4,7과 같은 숫자들에서 볼 수 있는 직선도 아주 작게 쪼갠다.
이렇게 잘게 쪼개진 조각들을 어떻게 인식하고 합치느냐에 대한 부분을 hidden layer에 기대해 볼 수 있다.

꼭 이미지 뿐만 아니라 음성처리 또한 여러 추상화된 단계로 나눌 수 있다.
음성분석은 특정한 소리들을 합쳐서 음절을 만들고, 음절을 합쳐서 단어를 만든다.
단어를 합쳐서 문장과 추상적인 생각들을 구성한다.
다시 돌아와서 !!
이 모델을 설계한다고 할 때, 한 층의 활성이 어떻게 다음 층에서의 정확한 활성을 이끌어내는 것일까?

목표는 픽셀을 각각의 조각들로 결합시키고,
각각의 조각들을 패턴(동그라미와 직선 등)으로 결합시키고,
그 패턴을 최종적으로 숫자로 결합하는 매커니즘을 만드는 것이다.!!!

2번째 층에서 하나의 특정한 뉴런이 이미지 외곽선이 있는지 없는지 판별해야한다고 했을 때,
과연 신경망이 어떤 변수를 가지고 있어야 할까?
또한 그것을 알기 위해 무엇을 조정할 수 있어야 할까?
여러 테두리(조각들)이 모여 원을 만드는 상황을 판별할 수 있을까?
❓
궁금하지⁉️
먼저 이 물음표들을 풀어가기위해
첫 층(layer)의 뉴런(각 픽셀의 값을 밝기로 입력받은 값)과,
현재 뉴런을 잇는 신경에
가중치를 부여(뉴런이 특정 영역의 픽셀에만 반응하도록 만들고자)할 것이다.
가중치는 그냥 숫자이다.
첫 층의 뉴런에서의 모든 활성치를 가져와서(아래 사진의 a) 각 신경의 가중치(w)를 주고 모두 더한다.
그 가중치를 평면상에 표현하면 아래 사진에서 양수는 초록 음수는 빨강이라고 했을 때,
픽셀의 밝기는 가중치의 느슨한 표현처럼 보일 수 있다.

우리가 원하는 부분(그림 상 흰 부분 = 확인하고 싶은 부분)제외하고, 다른 모든 픽셀의 가중치를 0에 가깝게 만든다.
그 후 각 픽셀에 가중치를 준 값의 합을 구하면, 그 영역의 픽셀에만 가중치를 주어 더한 것 같은 상황이 된다.
아래 사진처럼!

- 가중치를 0에 가깝게 만드는 이유: 특정 뉴런이 중요한 픽셀 그룹에만 집중하도록 하기 위해서.
- 가중치를 준 값의 합을 구하는 이유: 뉴런이 특정 패턴에 얼마나 반응하는지 정량화하고, 다음 층으로 전달하기 위해서.
그리고 그 테두리가 맞는지 확인하고 싶으면 주변의 픽셀에 음수 가중치를 주면 된다. 그러면 주변(테두리,,?)의 픽셀이 어두어지고, 중앙의 픽셀이 밝을 때 최대치를 얻을 수 있다.
이렇게 가중치를 준 값의 합을 계산해보면 어떤 값이든 나올 수 있으나 우리가 신경망에서 기대하는 값은 0-1사이의 값이므로,
가중치를 준 값의 합을 0-1의 숫자로 만들어주는 함수를 사용한다.

=> 로지스틱 방정식으로도 알려진 시그모이드 함수이다. 매우 작은 음수는 0에 가깝게 대응되고 매우 큰 양수는 1에 가깝게 대응되며 0 주위에서 계속 증가하는 함수이다.
그래서 뉴런의 활성화는 가중치의 합이 얼마나 더 양수에 가까운지에 따라 알 수 있다.
그런데 이 가중치의 합이 0이 기준이 될 때가 아닌, 10이 되어, 가중치의 합이 10보다 클 때 활성화되기를 원할 수도 있다.
이것은 활성화되지 않기 위한 조건을 다는 것이다.
이 때는 시그모이드 함수에 값을 넣기 전, 가중치에 -10을 더하는 것처럼 다른 음의 숫자를 더해줄 수 있다.
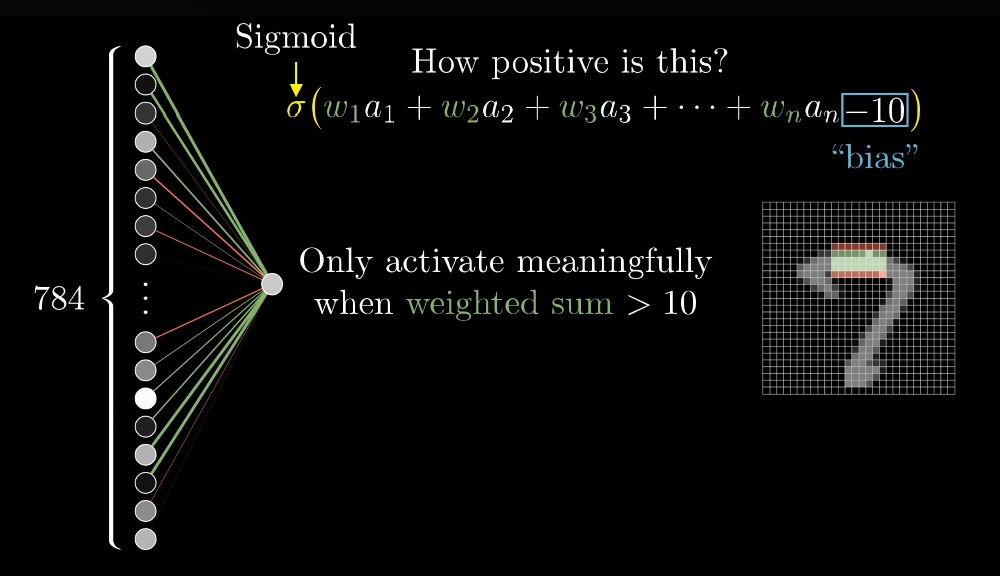
이렇게 더하는 숫자를 bias라고 한다.

가중치는 두 번째 레이어가 선택하려는 뉴런의 픽셀 패턴을 알려주며, bias는 뉴런이 활성화되기 위해 가중치의 합이 얼마나 높아져야하는지를 알려준다.
이게 단 한개의 뉴런에 대한 이야기였다 😂
layer의 모든 뉴런은 각각 첫 번째 레이어의 784개이 뉴런과 연결된다.
그리고 각각의 연결들은 각자의 가중치를 갖는다.

또한, 각각의 뉴런은 시그모이드 함수로 압축하기 전에 가중치에 더한 값인 bias를 갖는다.
이렇게 숨겨진 16개의 레이어는 각각의 16개의 bias를 가진 784*16개의 가중치를 의미한다.

'Learning' -> 컴퓨터가 실제로 해당 문제를 스스로 해결하기 위해 수많은 수치들을 찾기 위한 알맞는 환경을 얻는다는 것을 의미한다.
거의 첫 번째 영상의 끝이 보인다 ~!
조금만 더 힘내고🔥
이를 직접 설계한다고 생각해보자.
네트워크가 예상했던 것처럼 작동하지 않을 때,
가중치와 bias가 실제로 무엇을 의미할지 조금이나마 생각해두는 것이
구조를 어떻게 바꿔야 개선시킬 수 있는지 생각해보는 시작점이 될 수 있다.
네트워크가 작동하기는 했지만 예상했던 이유때문이 아니라면,
가중치와 bias가 어떤 것인지 파고드는 것이 우리의 가정을 시험하고 무엇이 가능한지 시험해볼 수 있게 해준다.
함수가 적기 복잡할 수 있다.

이를 풀어보기 위해
한 층이 활성화되는 정도를 열벡터로 모으고, 가중치를 모두 모아 행렬로 나타낸다.

행렬의 각 열은 한 층과 다음 층의 특정 뉴런의 연결을 나타낸다.
이것은 가중치들에 따라 활성화된 정도를 더한 것이 행렬 벡터곱을 하여 나오는 열벡터의 각 원소에 대응한다는 것을 의미한다.

bias를 독립적으로 각각의 값에 더하는 것으로 표현하는 대신,
bias를 전부 모아서 열백터로 만들고 백터 전체를 행렬 벡터 곱에 더하는 것으로 표현한다.

마지막으로 시그모이드를 이 바깥에 감싸준다. 이러면 시그모이드 함수를 결과 벡터 내의 원소들에 각각 적용하는 것이 된다.
그래서 가중치 행렬과 벡터들을 각각의 기호로 나타내면 활성화된 정도가 한 층에서 다른 층으로 어떻게 전달되는지를 짧고 간단한 식으로 나타낼 수 있게 된다.
다행히도 많은 라이브러리들이 행렬곱을 최적화하므로 관련코드를 쉽고 빠르게 만들 수 있다.
* 시그모이드 함수의 사용 : 초기 네트워크는 시그모이드 함수를 가중치가 적용된 합들을 0-1로 압축하기 위해 사용됐고, 뉴런이 활성화되고 비활성화되는 생물학적인 현상을 모방한 것.
그러나 현대의 네트워크들은 시그모이드 함수를 잘 쓰지 않는다. 조금 구식인 듯하다. 대신 훈련시키기 쉬운 ReLU 함수를 쓴다.
ReLU 는 Recitified Linear Unit(선형 정류 유닛)이다. 그냥 0과 a에 max 함수를 취한건데 a는 뉴런의 활성치를 나타내는 함수이다.
이것또한 뉴런이 생물학적으로 어떻게 활성화되고 비활성화되는지 모방한 것과 같아서 임계값을 넘기면 항등함수를 출력하고 넘기지 못하면 0을 출력한다. 시그모이드 함수로는 신경망 훈련이 잘 되지 않아서 ReLU로 학습했는데 deep neural network에서 잘 작동했다.
=> 정리
목표는 손글씨로 적은 숫자를 인식시키기이다. 이 숫자손글씨 이미지는 28*28 픽셀로 이루어져있고 각 픽셀은 0-1 사이의 밝기를 갖는다.
이것이 입력층의 784개 뉴런의 활성치를 결정한다.
다음층에 있는 뉴런 가각의 활성치는, 가중치와 이전 층의 활성치를 곱한 것들의 총합과 bias의 합에 의해 결정된다.
그리고 이 합에 시그모이드 함수나, ReLU 함수를 취한다.
결론적으로 임의로 설정한 각각 16개의 뉴런들로 구성된 두개의 hidden layer는 13000여개의 조정가능한 가중치와 bias 를 가지고있으며,
이 값들은 신경망이 실제로 어떻게 작동할지를 결정한다.
우리는 신경망이 주어진 숫자를 분류할 때, 마지막 충에서 가장 밝은 10개의 뉴런 중 하나의 숫자와 대응시킨다.
우리가 층 구조의 의의를 기억한다면, 2번째 층에서는 숫자의 조각들을 찾아내고 3번째 레이어에서 조각들의 패턴을 찾아낼 수 있다. 그리고 마지막으로 패턴을 조합하여 숫자를 찾아낸다.
-스터디 발표 미팅 ppt 중, 해당내용 첨부-


'💻 본업(컴공생) 이야기 > 머신러닝 - 딥러닝 이야기' 카테고리의 다른 글
| [CNN 공부하기] AlexNet, VGGNet, ResNet 은 뭘까? (2) | 2025.02.11 |
|---|---|
| [랩_스터디 과제 3] Gradient descent (경사하강법), how neural networks learn? 🧠 (2) | 2025.01.21 |
| [랩_스터디 과제 2] 발표준비 (0) | 2025.01.11 |
| [랩_스터디 과제 2] Decision Tree Regression (1) | 2025.01.11 |
| [랩_스터디 과제 2] Decision Tree Classification (1) | 2025.01.11 |