https://youtu.be/ZVR2Way4nwQ?si=W86UJdz3jLUoDCH0
위 영상을 통한 기록
어떤 알고리즘도 경험, 즉 데이터 없이 학습할 수 없기 때문에, 학습을 위한 데이터가 필요하다.
데이터 셋은 각각 x₀ (가로축)와 x₁ (세로축)에 있다. 그리고, 초록색과 빨간색의 두 개의 클래스로 존재한다.
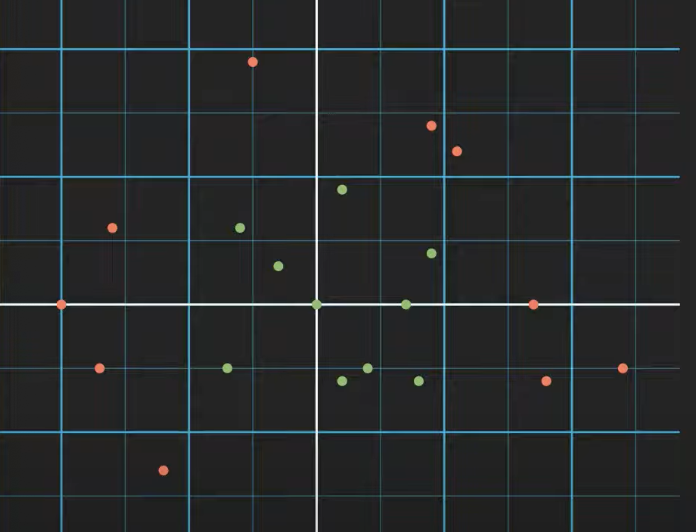
이 두 개의 클래스는 선형적으로 분리할 수 없다. 즉, 단순히 직선으로 두 클래스를 분리할 수 없다는 것이다.
이 문제는 결정 트리(Decision Tree) 를 통해 해결할 수 있다.
결정트리 : 이진 트리(Binary Tree)를 말하며, 데이터가 순수한 리프 노드(Pure Leaf Nodes)가 될 때까지 반복적으로 분할하는 것.
위에서 말한 ' 순수한 리프 노드'는 하나의 노드에 한 종류의 클래스만 존재하는 것을 의미한다고 합니다. (예: 초록색 데이터만 포함된 노드나 빨간색 데이터만 포함된 노드)

이렇게 선형으로는 분류할 수 없는 데이터의 분포들을 결정트리를 통해, 각각의 조건을 통하여 순수 리프노드를 만들어가며 훌륭한 분류를 해나갈 수 있다. 위 첨부된 사진처럼 말이다.
이 영상을 보며, 두 클래스를 효율적으로 나누기 위해서는 조건을 잘 적는 것도 정말 중요하겠다는 생각을 했다.
트리를 이용해 두 클래스를 잘 나누는 조건을 잘 정하는 방법은 무엇인지 궁금해졌고, 이것이 성능과 어떠한 관련이 있는지 정확히 알고싶어졌다.
내가 찾아본 영상에 따르면 왼쪽 그래프와 같이 나뉜 것 같다.

동작 방식:
- 데이터를 여러 조건에 따라 나누면서 트리를 생성한다.
- 각 노드는 데이터를 나누는 기준(조건)을 포함하며, 최종적으로 순수 리프 노드에 도달할 때까지 분할 과정을 반복한다.
중첩 조건문의 역할:
결정 트리를 코드로 나타내면, 중첩 조건문과 유사하다. 예를 들어,
- 첫 번째 조건으로 데이터를 x₀ 값에 따라 나누고,
- 두 번째 조건으로 x₁ 값을 기준으로 나누는 방식.
- 엔트로피(Entropy)
- 엔트로피는 정보의 불확실성을 측정하는 지표이다.
- 엔트로피가 높을수록 데이터가 섞여 있음을 의미하며, 엔트로피가 낮을수록 데이터가 더 순수해짐을 의미한다.
- 엔트로피를 줄이는 방향으로 데이터를 분할하여 순수 리프 노드를 만들고자 한다.
- 한 노드 안에 한 가지 클래스만 존재할 때, 그 노드의 엔트로피는 0이다.
- 즉, 순수 리프 노드에서는 더 이상 데이터를 나눌 필요가 없다.

- 정보 이득(Information Gain)
- 정보 이득은 데이터를 나눌 때 감소한 엔트로피의 양을 의미한다.
- 모델은 가능한 모든 분할 기준을 시도한 후, 정보 이득이 최대화되는 기준을 선택한다.
- 즉, 정보 이득이 가장 큰 분할이 최적의 분할이다.

정보 이득을 계산하는 과정
- 전체 엔트로피(Parent Node Entropy)
- 초기 데이터의 혼합 상태를 측정.
- 각 자식 노드의 엔트로피(Child Node Entropy)
- 데이터를 특정 기준으로 나눈 후 각 노드의 엔트로피를 계산.
- 정보 이득(Information Gain)
- 전체 엔트로피에서 각 자식 노드의 엔트로피(가중평균 값)를 뺀 값.
- 정보 이득이 클수록 해당 분할 기준이 데이터를 더 효과적으로 나눌 수 있음을 나타낸다.
성능과의 관련성
결정 트리의 성능은 분할 기준의 선택에 따라 크게 달라진다.
- 최적의 조건을 선택하면, 트리는 더 적은 단계에서 순수 리프 노드에 도달하며 효율적으로 학습할 수 있다.
- 반면, 잘못된 조건을 선택하면 트리가 비효율적으로 분할되거나, 데이터가 제대로 분류되지 않을 수 있다.
이를 방지하기 위해, 최적의 임계값(threshold)을 학습하고, 정보 이득을 기준으로 가장 효율적인 분할 방법을 자동으로 선택하도록 설계된다.
https://colab.research.google.com/drive/1RzxGPZM05s3LAd2aGL9K9tsCyH9FXgy8?usp=sharing
Decision Tree Classification in Python
Colab notebook
colab.research.google.com
'💻 본업(컴공생) 이야기 > 머신러닝 - 딥러닝 이야기' 카테고리의 다른 글
| [CNN 공부하기] AlexNet, VGGNet, ResNet 은 뭘까? (2) | 2025.02.11 |
|---|---|
| [랩_스터디 과제 3] Gradient descent (경사하강법), how neural networks learn? 🧠 (2) | 2025.01.21 |
| [랩_스터디 과제 3] Deep learning (introduction) (2) | 2025.01.21 |
| [랩_스터디 과제 2] 발표준비 (0) | 2025.01.11 |
| [랩_스터디 과제 2] Decision Tree Regression (1) | 2025.01.11 |