3주차 수요일
https://youtube.com/playlist?list=PLUl4u3cNGP60B0PQXVQyGNdCyCTDU1Q5j&si=iOUuKMchJz8QbFEE
MIT 6.S897 Machine Learning for Healthcare, Spring 2019
Instructors: David Sontag, Peter Szolovits View the complete course: https://ocw.mit.edu/6-S897S19 Introduces students to machine learning in healthcare, the...
www.youtube.com
머신러닝 기술을 통해서 의료사회를 어떻게 혁신 할 수 있을까?
이 분야에 관심을 갖게 된 각자의 사연들이 있는 것 같다. 암판정을 받았지만 매우 초기로 진단되어 상태를 기다려보는 것이 좋겠다고 판단했지만, 다른 합병증으로 사망에 이르렀다거나 등등 말이다.
이런 부분은 머신러닝 기술이 도움이 될 수 있을 것 같다.
의료분야에서 머신러닝은 퍼즐의 한 조각에 해당하고, 이것이 정답이 될 수는 없다. 물론 다른 영역들의 기술발전도 매우 중요하다는 것이다.
이를 전제로 강의를 시작한다.
1. 머신러닝과 의료분야에서의 배경지식
2. 왜 지금?
3. 머신러닝이 헬스케어를 어떻게 변화시킬 수 있을 것인가
4. 머신러닝 헬스케어에 대한 특이한 점
5. 머신러닝 헬스케어의 차이저과 고유한 점
1. 머신러닝과 의료분야에서의 배경지식
-의료분야에서 인공지능이 활용되기 시작한 것은 1970년대
ㄴ> 스탠포드에서 개발한 MYCIN 시스템 : 감염을 일으킬 수 있는 박테리아를 식별한 후, 해당 박테리아에 적합한 치료법을 찾아내는 것 -> 머신러닝 기술이 69% 당시 가장 좋은 확률로 치료법을 찾아냄
- 1980 스탠포드의 사례
ㄴ데이터중심적 접근방식을 취해 의학적 발견을 시도한 흥미로운 사례
류마티스 관절염은 만성질환이자 자가면역 질환인데, 이를 앓는 환자들의 질병 등록부라는 데이터베이스가 있음
각 환자에 대해 기록함 무릎통증 피로감 등등,,
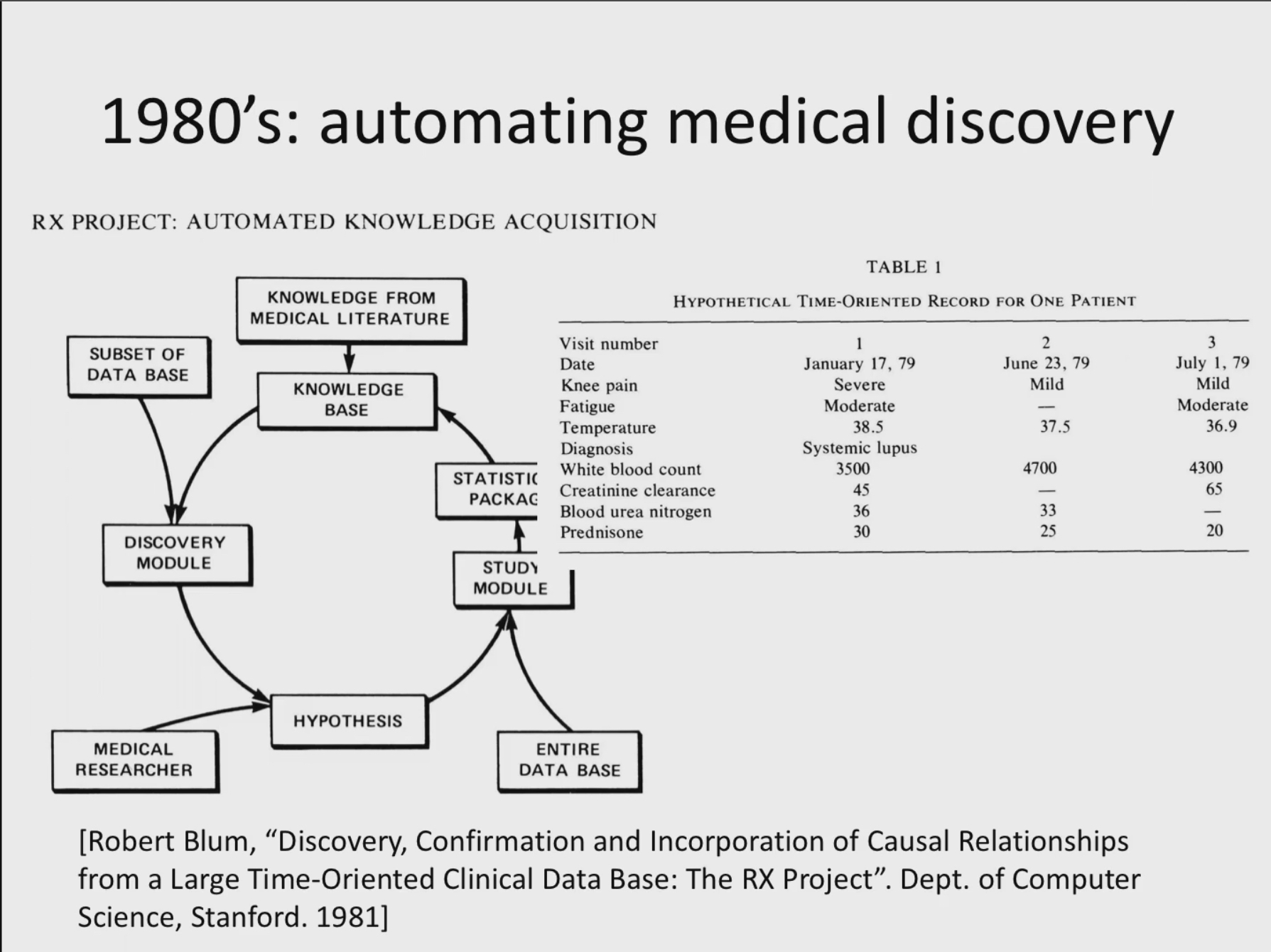
실제 환자의 진단은 전신성 루푸스라는 다른 자가면역 질환이었음
이 때도 각 환자의 질환이나 증상, 그리고 투여하고 있는 약에 대해서 종이에 기록하고 있었음
후에 이 기록들은 컴퓨터에 들어왔음
그 때부터 질문을 던지고 새로운 발견을 할 수 있는 가능성이 생김
--> 어떤 측면이 다른 측면을 유발할 수 있는지에 대한 인과적 가설을 세우는 발견모듈이 있었음
--> 그 후, 해단 인과 가설의 통계적 타당성을 확인하기 위해 몇 가지 기본 통계를 수행함
--> 그 후, 이를 도메인 전문가에게 제시하여 이것이 의미가 있는지 확인함
--> 수용된 지식에 대해서는 학습한 지식을 사용하여 반복하고 새로운 발견을 시도한다.
==> 프레드니손이 콜레스트롤을 증가시킨다는 것
데이터 중심 접근 방식의 아주 초기 사례
1990 년도 신경망이 인기를 얻기 시작함
- 1990년도 한 해에만 다양한 의학적 문제에 신경망을 활용한 연구가 88건이나 발표됨
-접근방식의 차별점은 피처 수가 매우 작았다는 것
- 머신러닝에 사용하기 위해 수동으로 구조화된 데이터
- 자동이 아니었기 때문에 데이터를 수집하기 위해서 보조할 사람이 필요했음
-머신러닝에 사용된 각 연구의 샘플 수는 매우 적었음
-> 임상작업흐름에 맞지 않았고 수동으로 충분한 트레인 데이터를 얻는 것이 어려웠음
: 한 기관에서 트레인 데이터 수집, 모델학습, 모델검증에 엄청난 노력을 기울이고, 다른기관에 적용하면 오히려 효과가 떨어짐
그래서 연구된 다양한 영역은 : 유방암, 심근경색, 요통, 입원, 피부종양, 두부손상, 치매예층 당뇨병 진행도 이해 등
2. 왜 지금?
- 지난 30~40년 동안 실패하는 상황을 겪어왔지만 왜 지금은 성공할 가능성이 있을까?
그 이유는 '데이터' 이다.
과거에는 의학분야에서 인공지능을 활용한 작업의 대부분이 데이터 중심이 아니었다.
임상분야의 전문가로서 최대한 많은 분야의 지식을 이끌어내려는 시도에 기초했다.
데이터는 전자적으로 수집되고 있으며, 이를 바탕으로 머신러닝 모델 연구를 시도할 수 있는 기회가 제공된다.
환자에 대한 데이터를 수동으로 입력하는 대신, 전자 형태로 제공되는 데이터에서 자동으로 데이터를 추출할 수 있는 머신러닝 알고리즘 배포를 시작할 수 있는 기회가 생긴다. (NLP) ? --> 음성녹음을 통한 병원진료 차트화, 자동약물투여 기계가 있다면 약물투여 데이터도 기록할 수 있음 등등
- MIT 에서는 ECS 및 의료공학 연구소의 로저마크 교수가 주도하여 PhysioNet 또는 Minic 이라고 알려진 데이터베이스를 만드는 주요한 노력을 기울였음. Mimic에는 4만명 이상의 환자와 중환자실 데이터가 포함되어 있음. 영상, 이미지, 테이블데이터, 등등
** 데이터 베이스의 중요성 **
공개적x 한 기업에서 구축한 데이터베이스 => Truven Market Scan DB, 이후 IBM 에 인수됨
전자의료기록에서 생성되는 것이 아니라 일반적으로 보험 청구를 통해 생성됨. 의사를 만날 때마다 방문에 대한 기록이 청구서와 함께 보관된는 것이 일반적임. 의료제공자는 어떤 문제로 인해 어떤 시술이 들어갔고 어떤 약물을 썼는지, 검사비용 등등 종합적인 데이터를 볼 수 있음
데이터를 수집 -> 연구목적으로 재판매
이 때 데이터의 가장 큰 구매자 중 하나는 제약산업임 (큰 돈을 들여 데이터를 산 사람뿐만이 연구를 할 수 있다는 제한이 있음)
이에 대해서는 '정책'이 도움을 줄 수 있을 것임
그러나 MIT에서는 IBM Watson AI 연구실 덕분에 데이터를 조금은 쉽게 얻을 수 있을 것이라고..
* 대규모 데이터 세트를 생성하는 다른 '이니셔티브'가 많이 있음
미국에서 정말 중요한 이니셔티브는 오바마 대통령의 정밀 의학 이니셔티브임

전자의료기록과 건강보험 청구 데이터가 모두 포함됨
데이터는 임상기록과같은 비정형 데이터부터 영상, 실험실, 검사, 생체신호까지 다양하게 있음
임상데이터라고 생각했던 것들이 실제로 생물학적 데이터라고 생각하는 것과 긴밀하게 연결되기 시작함
-> 따라서 유전체학과 단백체학으로 부터 얻은 데이터는 임상연구와 임상 실무에서도 모두 중요한 역할을 하기 시작함.
현대 시대에는 전자 건강 기록(Electronic Health Records)이 활성화되어 수동으로 작업하던 데이터들을 컴퓨터를 통해 병원에서 기록하고 관리할 수 있게 되어, 데이터 수집이 편리하고, 또 방대하게 되어 이전의 데이터수집에 대한 문제점이 해소되어가며, 데이터 베이스의 중요성이 대두되었다.
대표적인 대규모 데이터,
(mit에서 개발되어 연구목적으로 사용되고 있는 중환자실 환자의 데이터를 수집한 오픈 데이터베이스) MIMIC,
(truven회사에사 개발하고 ibm에 인수된 의료보험 청구 데이터를 기반으로 한 데이터베이스)Truven MarketScan,
(미국 정부가 시작한 데이터 프로젝트로 100만명 이상 환자 데이터를 수집한)All of Us Initiative와 같은 대규모 데이터베이스가 연구에 활용되었다.
또한 (세계보건기구(WHO)에서 개발한 질병 및 증상에 대한 국제 표준 분류 체계) ICD-10,
(실험실 검사 결과를 표준화하기 위한 국제 코드 시스템인) LOINC,
(미국 국립의학도서관(NLM)이 개발한 의료 용어를 통합하여 서로 연결하는 시스템인 )UMLS 등 데이터 표준화로 더 나은 분석이 가능해졌다.
FHIR와 OMOP 같은 데이터 교환 모델은 병원 간 데이터 공유를 촉진할 수 있도록 도와주었다.
데이터 수집 방식의 변화는 머신러닝 기술 발전에 큰 기회를 제공해주었다.
EHR 시스템을 통해 자동으로 기록하여 대규모 데이터를 제공하여
더 정밀한 알고리즘 개발과 분석을 할 수 있게 해주었다.
3. 머신러닝이 헬스케어를 어떻게 변화시킬 수 있을 것인가
그렇다면 머신러닝이 헬스케어를 어떻게 변화시킬 수 있을까?
헬스케어에서 머신러닝의 잠재적 활용 방안은 다음과 같다.
1) 만성질환 관리
당뇨병, 알츠하이머, 암 등을 조기에 진단하고, 환자를 지속적으로 모니터링할 수 있다.
예를 들어 머신러닝 모델은 환자의 병력, 유전자 데이터, 생활 습관 데이터를 분석해 질병 발생 가능성을 조기에 예측할 수 있다.
신경망 모델을 통해 암 이미징 데이터에서 초기 암종을 탐지하거나,
자연어 처리(NLP) 기술을 통해 진료 기록에서 위험 요인을 찾아낼 수 있고
웨어러블 기기에서 실시간으로 수집되는 데이터(심박수, 혈당, 활동량 등)를 머신러닝 알고리즘이 분석하여 이상 패턴을 감지할 수 있다.
이를 통해 환자 상태의 급격한 변화나 악화를 조기에 알릴 수 있다.
2) 신약 개발 및 질병 연관성 발견
대규모 생물학적 데이터(예: 유전자, 단백질 데이터)를 학습해 질병의 분자적 기전과 약물의 효과를 예측할 수 있다.
3) 환자 맞춤형 치료입니다.
- 머신러닝 모델은 개별 환자의 유전자, 생리 데이터, 병력 등을 분석하여 특정 치료법의 효과를 예측할 수 있다.
- 예를 들어, 암 환자에게는 유전자 프로파일링을 기반으로 특정 약물(타겟 치료제)의 반응성을 예측하여 치료 계획을 수립할 수 있다.
4. 머신러닝 헬스케어에 대한 특이한 점
헬스케어에서 머신러닝을 활용하는 데는 여러 도전 과제가 있다.
데이터 부족 문제 - 희귀 질환의 경우 데이터가 부족하므로 반지도 학습이나 전이 학습이 필요한다.
데이터 통합의 어려움 - 환자가 병원을 옮길 때 데이터가 제대로 이전되지 않는 문제가 있다.
임상 통합의 복잡성 - 병원의 EHR 시스템과 머신러닝 모델을 통합하기가 어렵다.
윤리적 문제 - 데이터 접근성, 재현성, 환자 프라이버시와 같은 문제가 해결되어야 한다.
5. 머신러닝 헬스케어
머신러닝은 헬스케어에서 다음과 같은 잠재력을 가지고 있다.
- 의료비 절감 -> 최적화와 효율적인 자원 관리로 의료비,수술시간 등을 줄일 수 있다.
- 환자 결과 향상 -> 조기 진단과 맞춤형 치료로 환자의 삶의 질을 높일 수 있다.
- 질병 연구 발전 -> 신약 개발과 새로운 질병 발견을 가속화할 수 있다.
하지만 헬스케어의 특유한 어려움, 예를 들어 데이터 통합과 윤리적 문제를 극복하는 것이 필수적이다.
따라서 의료 데이터를 더 열심히 이해하고, 이를 실제 문제에 적용할 수 있는 기술을 개발해야 한다는 것을 느낄 수 있었다.
'💻 본업(컴공생) 이야기 > 의료 데이터 공부 이야기' 카테고리의 다른 글
| [의료 데이터 🩺] 4. Risk Stratification (위험 계층화), Part 1 (1) (8) | 2025.02.03 |
|---|---|
| [의료 데이터 🩺] 2-3. Clinical Care/Data (0) | 2025.02.03 |