https://youtu.be/DS97JV_o0Fs?si=uJBs4CC2fPbFVsKN
https://youtu.be/0UFwGJe6ubg?si=uVPirmxkYD3DWoCq
피피티는 유튜브 강의에서 사용하신 피피티를 아주 많이 참고하여 발표 자료를 만든 것이다.
병원에서는 환자의 심박수, 혈압, 과거 병력 등등 다양한 데이터를 수집하여 지료에 사용합니다.
그런데 만약 그 데이터들이 부정확하거나, 잘못 분석되었다면 어떤 결과를 초래할까요?
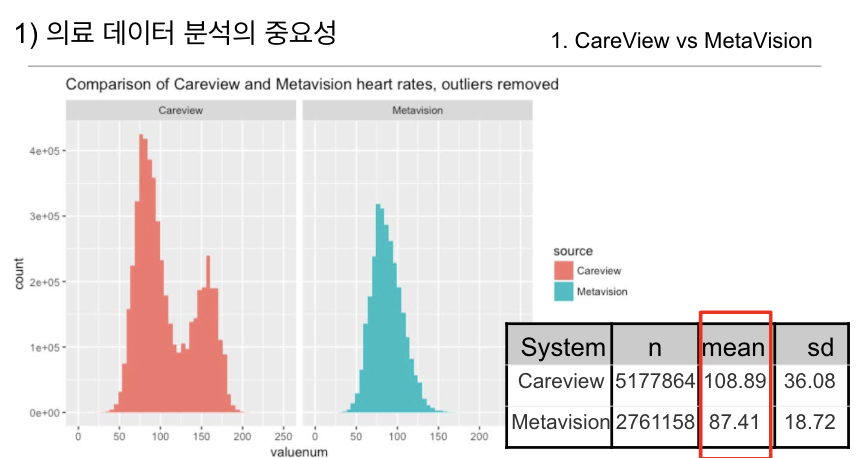
한 연구팀은 같은 병원에서 수집된 심박수 데이터를 분석하다가, CareVue 시스템에서는 심박수의 평균이 108.89, MetaVision 시스템에서는 87.41로 나타나는 차이를 발견했습니다.
같은 병원 데이터임에도 불구하고 이 차이가 발생한 이유는, 이 두 시스템이 데이터를 수집하고 저장하는 방식이 다르기 때문입니다. 이 사례는 의료 데이터의 수집 방식이 분석 결과에 얼마나 큰 영향을 미칠 수 있는지 보여줍니다.
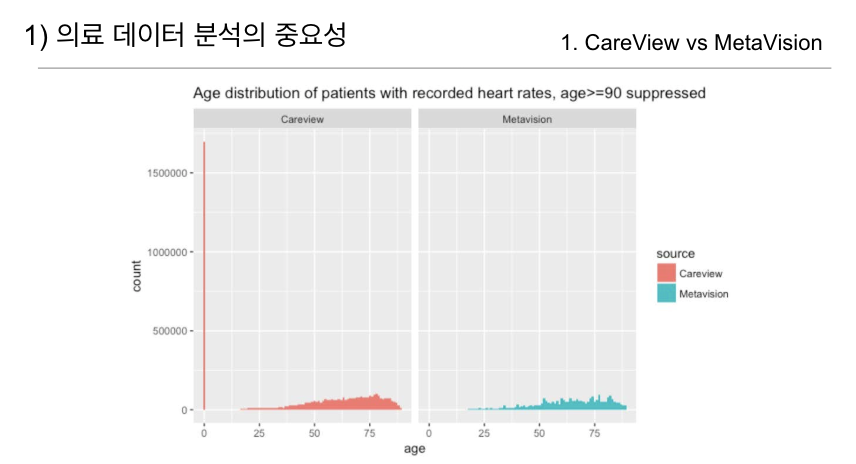
병원이 새로운 데이터 시스템으로 전환하는 과정에서 데이터 호환 문제는 흔히 발생합니다. 위 그래프의 왼쪽에 위치한CareVue 데이터에서는 신생아 환자의 비율이 상대적으로 높게 나타나는 것을 볼 수 있습니다.
이 차이는 두 시스템이 데이터를 관리하는 방식에서 기인하며, 신생아 데이터를 처리하는 방식을 구분하지 않으면 결과 해석에 오류를 초래할 수 있습니다
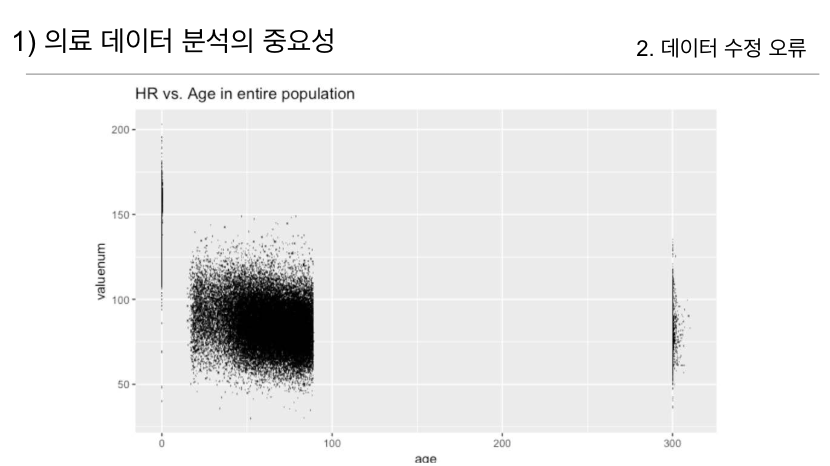
또 다른 사례로는, 환자 데이터에서 '300세 환자'가 발견된 경우입니다. 이 환자들은 실제로 300세가 아니라,
미국 HIPAA 규정에 따라 90세 이상 환자들의 나이를 일괄적으로 300세로 수정한 사례입니다.
이러한 데이터 수정은 환자 개인 정보 보호를 위해 필요한 조치이지만, 분석 시에는 데이터의 특수성과 이러한 수정을 고려하지 않으면 오해를 불러일으킬 수 있습니다.
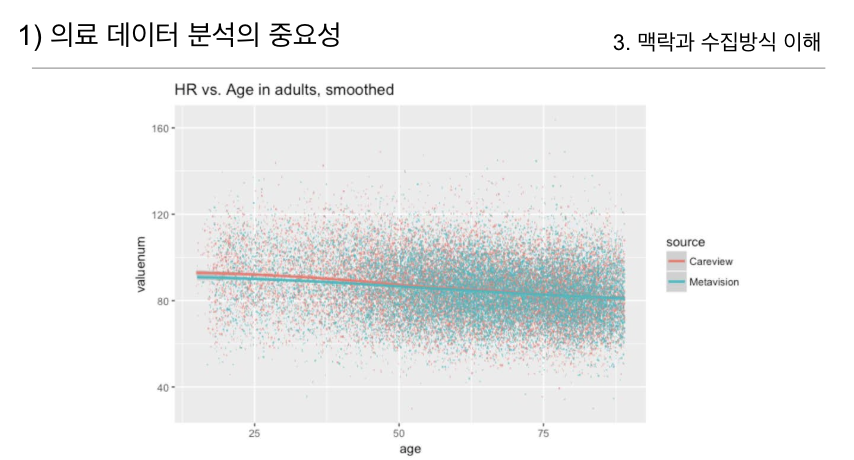
마지막으로, 나이와 심박수 간의 관계를 CareVue와 MetaVision 데이터를 통해 살펴본 그래프입니다. 앞서 본 두 시스템 간의 데이터 수집 차이를 고려했을 때, 최종적으로는 매우 유사한 패턴을 보였습니다.
이 사례는 데이터 분석에서 맥락과 수집 방식을 이해하는 것이 필수적임을 강조합니다. 잘못된 데이터 해석은 잘못된 결론을 초래할 수 있기 때문에, 데이터의 출처와 수집 방식을 항상 고려해야 합니다

이 환자의 경우 입원 초기에는 Full Code 상태였지만, 시간이 지나며 Comfort Measures로 변경된 것을 볼 수 있습니다.
환자의 상태 악화와 /가족과 의료진의 논의 결과일 가능성이 있습니다.
GCS(글래스고우 컴마 스케일)는 환자의 의식 수준을 평가하는 척도로, 다음 세 가지 영역에서 점수를 기록합니다:
- Verbal (언어 능력): 말하기 능력을 기준으로 평가.
- Motor (운동 능력): 명령에 따른 운동 조절 능력을 기준으로 평가.
- Eye (안구 움직임): 눈의 움직임 반응을 기준으로 평가.
초기에는 환자가 명령을 완전히 수행할 수 있었지만, 시간이 지남에 따라 능력이 점차 약화되고 혼란 상태에 빠지게 된 것을 알 수 있습니다.
4.채액측정입니다
- Platelet Count (혈소판 수), Creatinine (크레아티닌), White Blood Cell Count (백혈구 수), Neutrophil Count (호중구 수)
- 위 수치를 통해 환자의 체액 상태와 염증 수준을 확인할 수 있습니다
- 초기와 중기의 혈액 성분 변화는 환자의 상태 악화 또는 감염 발생 여부를 간접적으로 보여줍니다.
5. 약물투여기록으로
다양한 약물의 투여량과 속도를 시간 경과에 따라 나타냅니다.
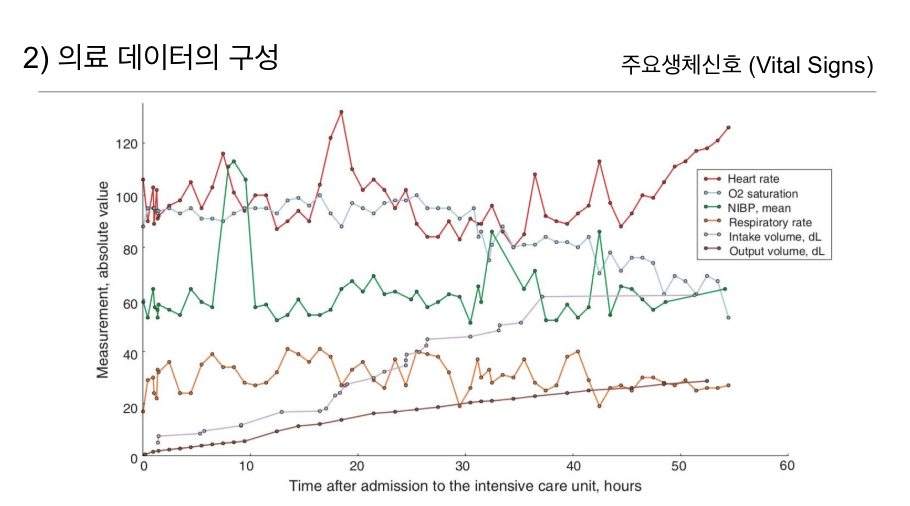
다음은 주요신체신호를 관찰한 데이터입니다.
심박수(Heart rate) , 산소포화도(O2 saturation), 평균 비침습 혈압(NIBP mean),
호흡수(Respiratory rate), 섭취량(Intake volume) , 배출량(Output volume).
만약
- 심박수나 호흡수가 비정상적으로 변동할 경우, 응급조치가 필요하다거나
- 산소포화도의 감소를 감지하고 환자의 호흡 기능에 문제가 있을 가능성을 염수할 수 있습니다니다.
이러한 생체신호 데이터는 환자의 상태를 종합적으로 모니터링하고 치료 방향을 조정하는 데 필수적인 역할을 합니다.
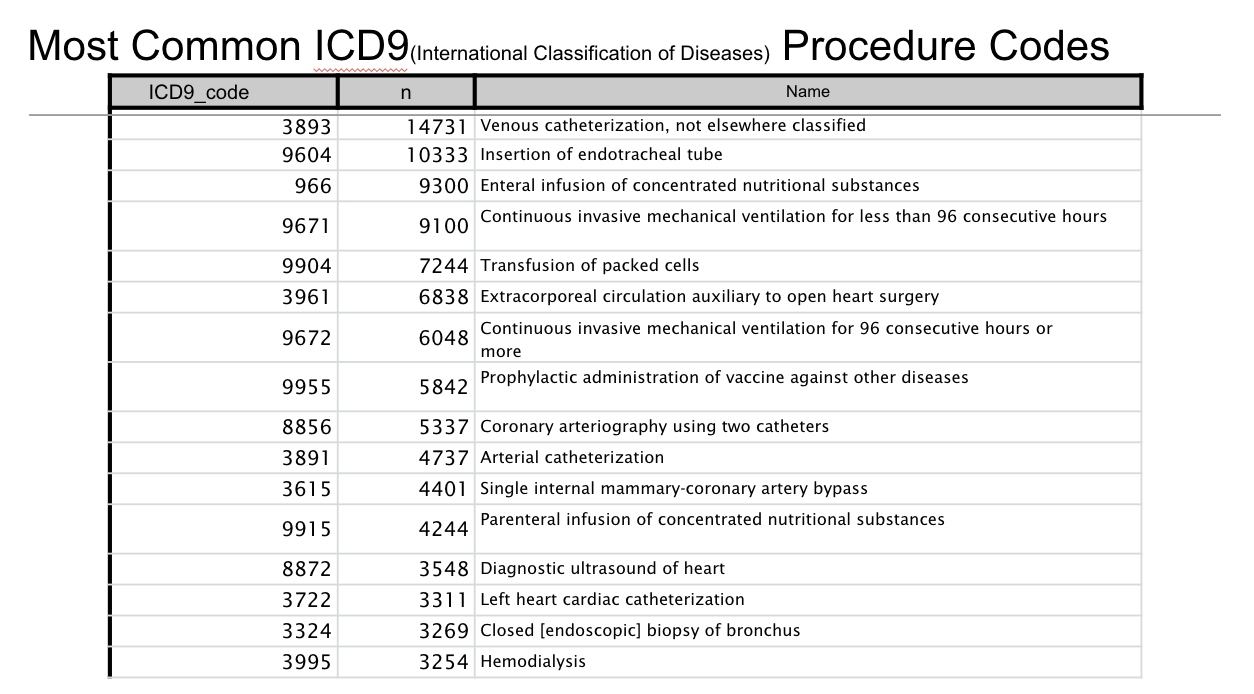
다음은 ICD-9에 대한 내용입니다.
ICD-9는 국제질병분류로, 세계보건기구에서 질병, 건강 상태 및 의학적 절차를 표준적으로 분류하기 위해 개발한 코드 체계입니다.
표에 보이는 내용은 고유한 ICD-9 코드에 따른 대표적인 의료 절차와 그 발생 빈도입니다.
(ICD-9 코드는 특정 의료 행위를 표준화하여 기록하는 데 사용되며, 표에는 병원에서 가장 자주 수행되는 절차들이 포함되어 있습니다.)
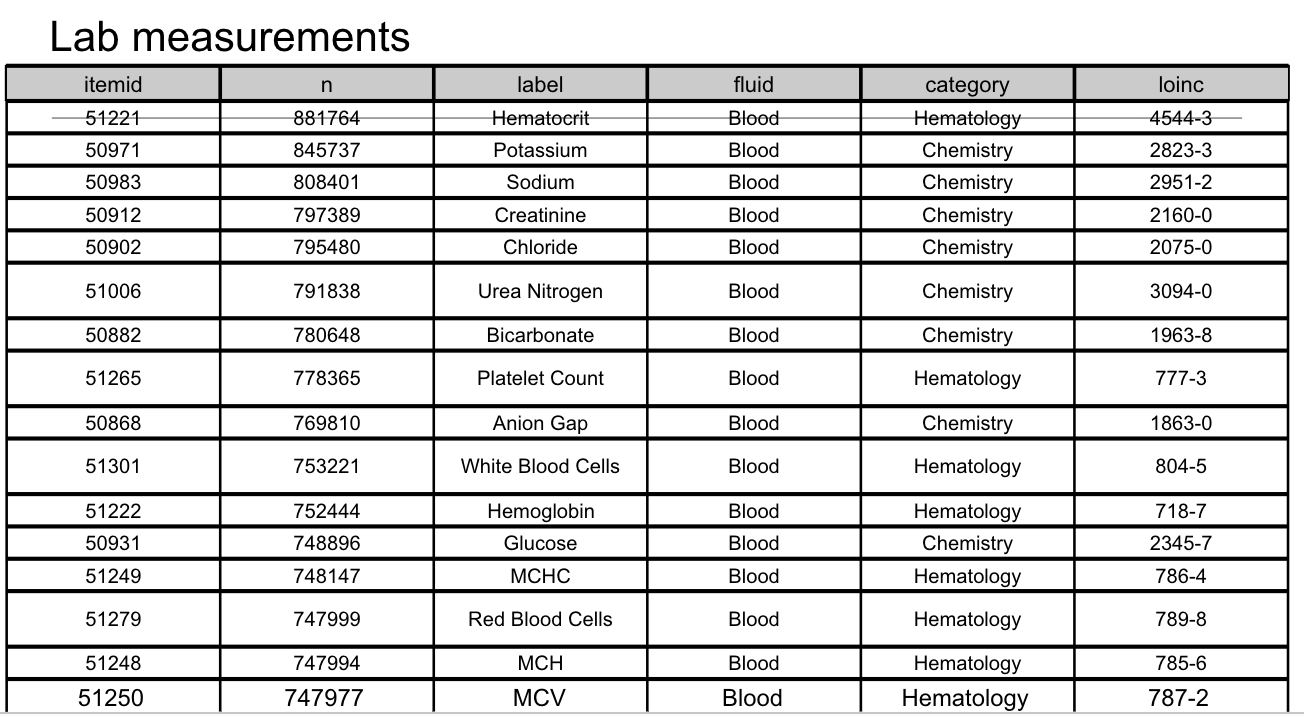
이 슬라이드는 환자의 실험실 혈액 검사 데이터를 나타내고 있습니다.
여기서 각 항목은 혈액에서 측정된 결과를 보여주며, LOINC 코드가 적용되어 있습니다.
LOINC는 (Logical Observation Identifiers Names and Codes) 약자로 의료와 실험실 데이터를 표준화하기 위해 만들어진 코드체계입니다
표에는 다음과 같은 열(column)이 있습니다:
- itemid: 각 실험실 검사 항목에 고유하게 부여된 ID입니다.
- n: 각 검사 항목의 데이터가 기록된 총 횟수를 나타냅니다.
- label: 검사 항목의 이름입니다. 예를 들어, Hematocrit, Potassium, Sodium 등이 있습니다.
- fluid: 검사된 체액의 종류로, 여기서는 모두 **Blood(혈액)**입니다.
- category: 검사 항목의 분류입니다. 주로 **Hematology(혈액학)**와 **Chemistry(화학)**로 나뉩니다.
- LOINC: 검사 항목의 국제 표준 코드로, 각 항목을 고유하게 식별하는 데 사용됩니다.
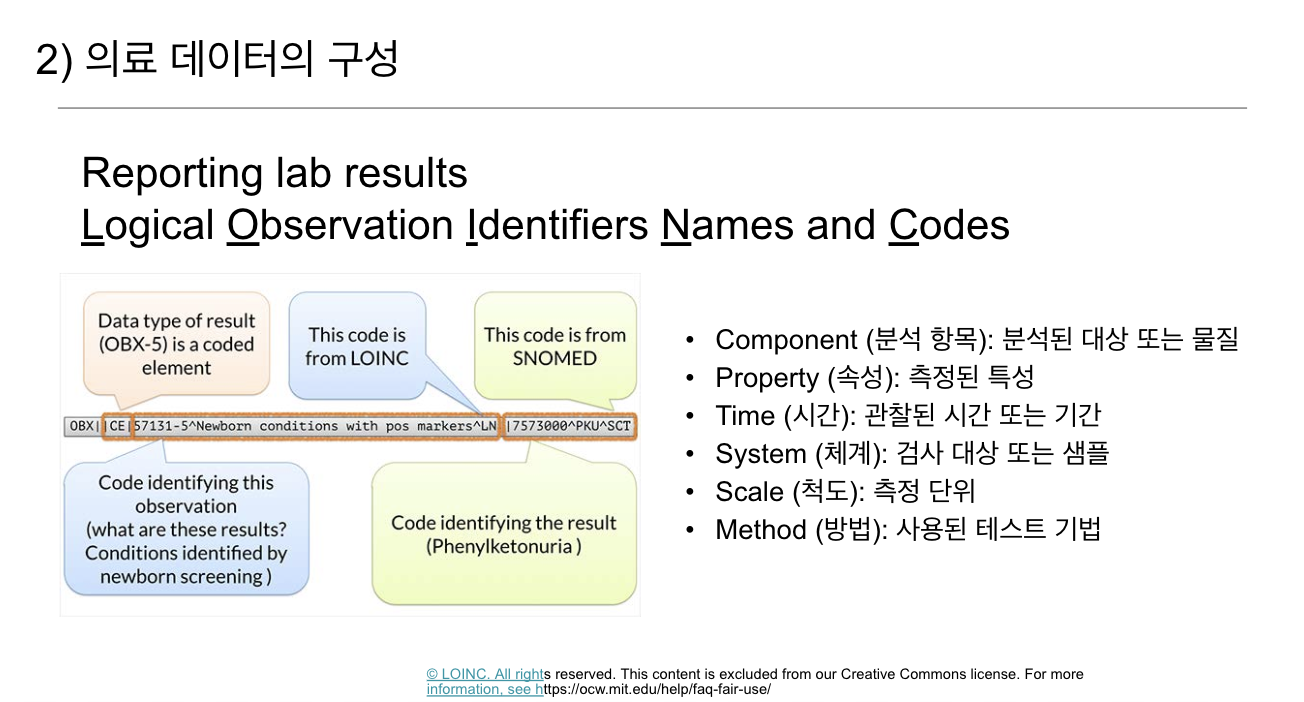
여기서 로잉크 시스템에 대해 조금 더 설명하도록 하겠습니다.
이 슬라이드는 LOINC 시스템에 기반으로 실험실 결과가 어떻게 표준화된 방식으로 기록되고 교환되는지를 보여주고 있습니다.
임상 실험실 결과와 기타 건강 관련 데이터를 표준화하고 상호 운용성을 높이기 위해 사용되는 코드 체계입니다. 이 슬라이드는 HL7 메시지 구조에서 LOINC 코드가 어떻게 사용되는지와 관련된 예시를 보여줍니다. 이를 통해 실험실 테스트 결과가 보고되는 방식과 데이터의 구성 요소를 이해할 수 있습니다.
데이터 유형 (OBX-5):
- OBX-5는 데이터의 결과 값을 담고 있는 HL7 메시지 필드로, 이 결과 값은 특정 코드 체계로 설명됩니다.
- 예를 들어, "Newborn conditions with pos markers"라는 관찰 값이 기록되었습니다.
LOINC 코드:
- LOINC 코드는 질문 또는 관찰된 항목에 대해 고유한 식별을 제공합니다.
- 예: 57131-5는 신생아 조건을 특정합니다.
SNOMED 코드:
- SNOMED 코드는 결과에 대한 답변을 나타냅니다.
- 예: 75730000은 "Phenylketonuria(페닐케톤뇨증)"라는 특정 질병을 식별합니다.
구성 요소(Components):
- 테스트에서 측정되는 분석 대상 또는 물질을 나타냅니다.
- 예: 신생아 상태(Newborn conditions).

이 슬라이드에서는 약물 데이터 표준화의 중요성과 도전을 다루고 있습니다.
먼저, NDC(National Drug Code)는 FDA에서 개발한 약물 코드 체계로, 10자리 숫자를 통해 약물의 제조사, 약물 형태, 패키지 크기를 나타냅니다.
하지만, 이 체계는 코드가 고갈되면서 확장하는 데 어려움을 겪고 있습니다. 이렇게,오래된 코드와 새로운 코드 간의 번역 문제와 혼란이 발생하고 있습니다.
반면, (Medical Dictionary for Regulatory Activities)는 국제 표준으로 개발되어 약물과 관련된 규제 정보를 공유하기 위한 매우 구체적인 의료 용어 체계입니다. 그러나 MedDRA와 NDC는 호환되지 않기 때문에, 병원 간 데이터 통합을 어렵게 만들고 있습니다.
이 사례는 의료 데이터 표준화가 기술적으로 복잡하며, 상호 운용성을 높이기 위한 노력의 필요성을 보여줍니다
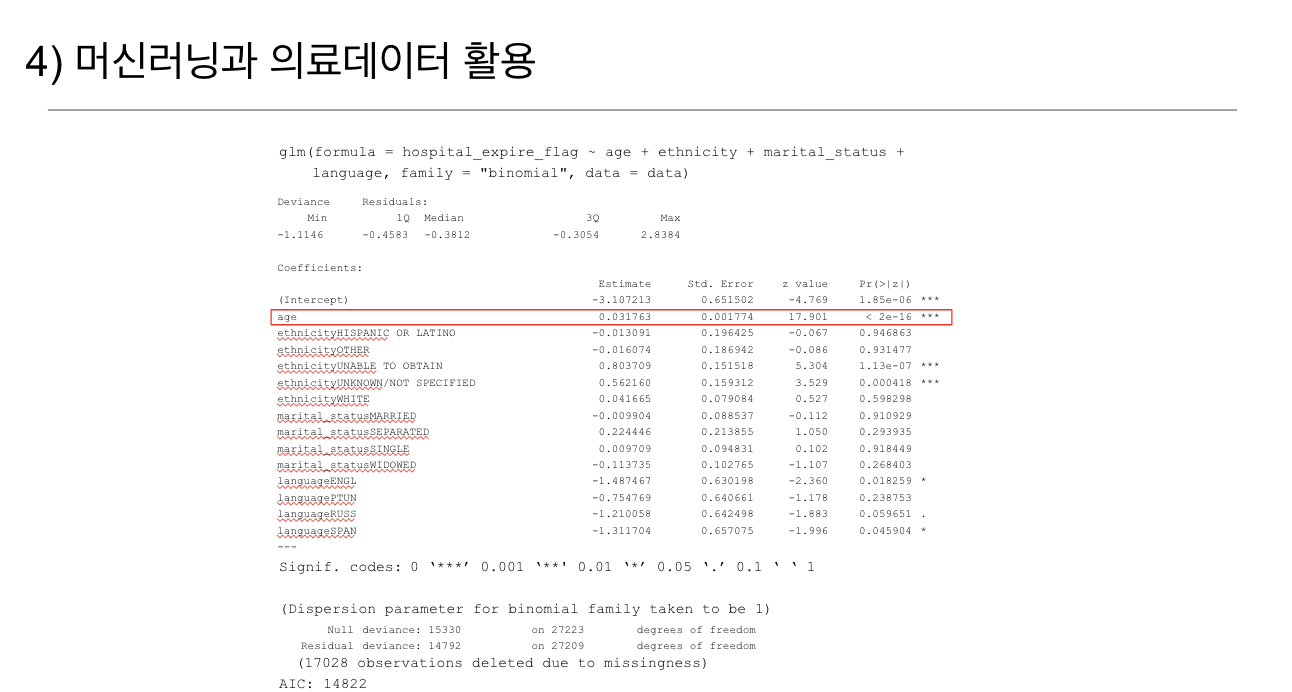
- 위 표는 로지스틱 회귀 모델(GLM)을 사용하여 병원 내 사망률과 인구통계학적 요소(나이, 민족, 결혼 상태, 언어 등)의 관계를 분석한 결과를 보여줍니다.
- 머신러닝 및 통계 모델은 의료 데이터를 활용하여 사망률 예측과 같은 중요한 임상적 의사 결정을 지원하는 데 사용됩니다.
- 특히, 나이가 병원 내 사망률에 가장 큰 영향을 미치는 요인으로 도출된 점은 의료 데이터 분석에서 통찰을 제공하는 핵심 사례입니다.
머신러닝의 실질적인 활용 사례로, 의료 데이터가 어떻게 임상적 의사 결정을 향상시킬 수 있는지를 볼 수 있었습니다
'💻 본업(컴공생) 이야기 > 의료 데이터 공부 이야기' 카테고리의 다른 글
| [의료 데이터 🩺] 4. Risk Stratification (위험 계층화), Part 1 (1) (9) | 2025.02.03 |
|---|---|
| [의료 데이터 🩺] 1. What makes Healthcare Unique? (6) | 2025.01.23 |